


There’s a lot of promotion around using analytics in eDiscovery. But, what exactly do they do? Today, as part of a two-part series, I’m breaking down the basics of Structured Analytics and how, when applied correctly, they can contribute towards an effective and efficient review. In our next Tuesday Tip, I will share the basics of Conceptual Analytics and how they differ.
Structured Analytics is based on text, making it an ideal method to quickly assess and organize documents during a review. This type of analytics works by comparing every word in an entire review set and identifying the similarities and differences between the documents. This is achieved in three ways:
1. Near Duplicate Detection
Near Duplicate Detection finds the similarities between all types of documents and identifies the percentage of duplicate text within the set. The most complete or longest document will be identified as ‘100’ in the Near Duplicate Similarity field. This document is deemed the ‘principal’ and what all other documents within the group will be compared to. Every other document in the set will be given a number to indicate its percentage of similarity to the Principal Document.
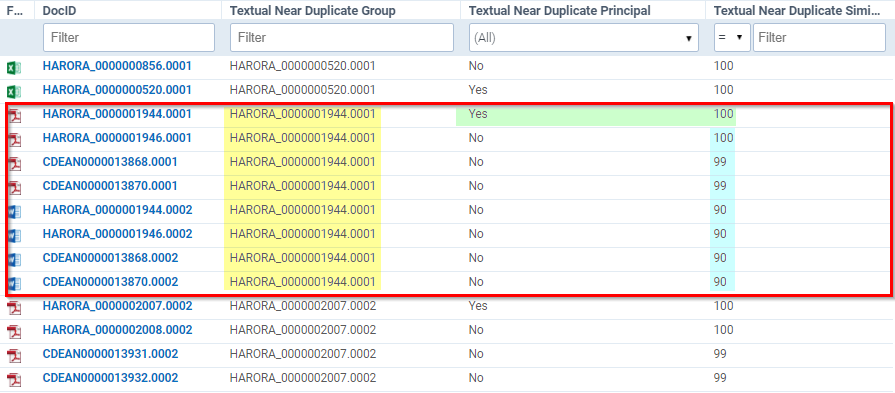
In the above example, we can see eight documents that have been identified in the same category — each of which has been given the same identifying number under the Textual Near Duplicate Group field.
The first document that is marked as ‘100’ is the Principal Document. Each subsequent document is being compared to that document’s contents. We also see that there is one document that is 100 per cent similar, two that are 99 per cent similar and four that are 90 per cent similar to our Principal Document. Note that, from the icons on the far left, these documents are a mix of PDF and Word files. When using Near Duplicate Detection, it doesn’t matter what the file types are. The content of what is within those documents is what’s important.
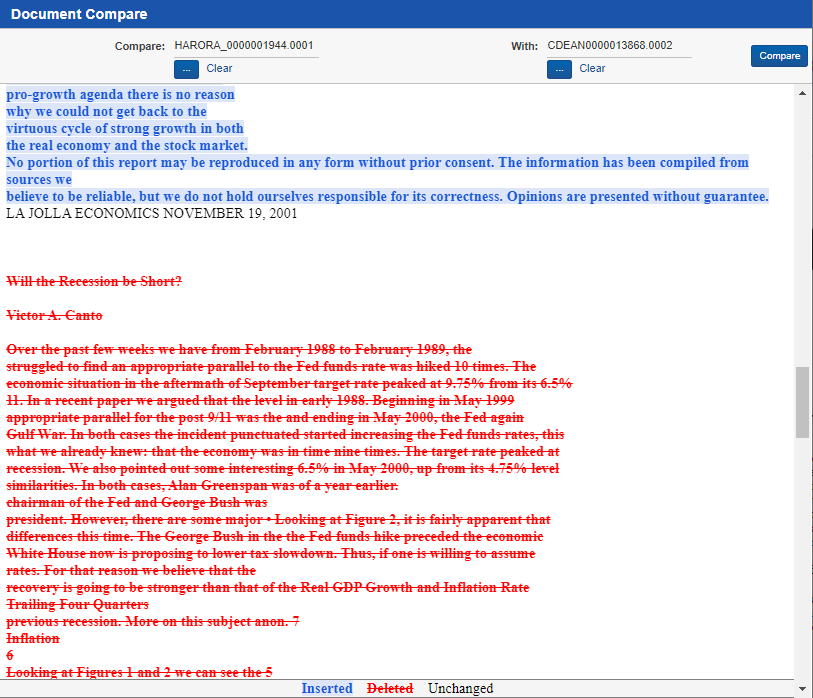
Though this example is from Relativity, most eDiscovery platforms will allow you to see a visual comparison between two documents. Near Duplicate Detection is most helpful when eliminating documents that are highly similar in text from your review process, as well as identifying where the changes lie in text-heavy documents such as agreements or contracts.
2. Email Threading
Email Threading is similar to Near Duplicate Detection in that it compares text between two documents. However, as its name suggests, it only takes emails into consideration. Though attachments are also indicated as part of an email thread group, the text of those documents is not included in the comparison. The benefit of email threading is that it allows you to easily view different emails within a chain, providing you with a high-level view of the different branches within an email thread including replies and forwards.
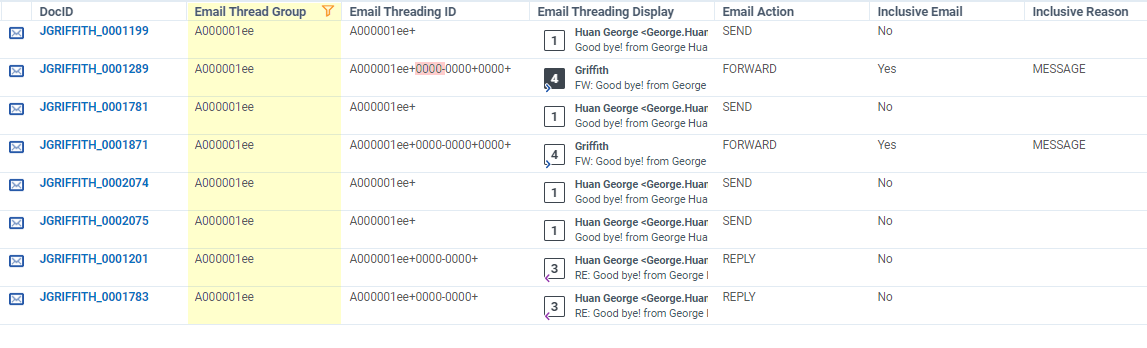
Here we have one group of emails that all belong in the same thread — all of which have the same identifier in the Email Thread Group. The next field, Email Threading ID, indicates the different emails and branches within the email chain. If one of the numbers changes within the thread, it becomes a new branch. You will see there are plus (+) and minus (-) signs within this field. The plus sign indicates whether that particular email exists within your data set. If it does not, it will have a minus sign (-) beside it. You will see that the second email (the first set of 0000 in the threading ID) has a minus sign. This means that email does not exist in the database. Furthermore, the Email Threading Display field indicates that the email from the thread is missing as we do not see “2”.
When it comes to Email Threading, the fields we want to pay attention to closely are the Inclusive Email and Inclusive Reason. Much like a Principal Document, an Inclusive Email is the most complete email within the chain which contains all other email content. You can have more than one Inclusive Email within the thread, and any responses to other emails or forwards will create new branches. When an email is indicated as ‘inclusive’, you will want to review it as it contains other text or attachments not found within the other emails. The Inclusive Reason will tell you why that email is inclusive. For example, it can indicate “Attachment” in the field, meaning that the email is inclusive because of an attachment within it. While the body of an email may appear in another email, the attachment that was sent originally would not appear in any responses. In the example above, we see that the Inclusive Reason is populated with “Message”, meaning that the content of that email is different from the others.

The above image is another illustration of the missing email and indicates which one is inclusive. Email Threading can increase efficiency in your review as you can choose to focus only on the Inclusive Emails and their attachments. Thus, not having to review the emails in between several times as they will already be included within the Inclusive Email.
3. Language Detection
Language Detection goes through the text of the document and identifies the potential languages that appear in the document. Some tools can identify all the languages that may appear while others will identify only the primary language. This is helpful when you are working on documents that come from different regions and countries as it can help prepare you to build a team that understands the identified languages for review purposes.
---
This Tuesday Tip should give you a solid understanding of what using Structured Analytics entails. Stay tuned for next month’s blog where we’ll be diving into the basics of Conceptual Analytics. Click here to subscribe to our blog so you’re notified as soon as it’s posted.
You may also be interested in...

The Top Six Most Common Sources to Consider Prior to a Data Collection
Here's where to find the data you need to successfully complete a collection. We include the most popular data sources, and address important factors to consider when collecting from each medium.

eDiscovery 101: 5 Easy Ways to Plan a Successful eDiscovery Project
If you're new to the world of eDiscovery, starting on your first project can be intimidating. Here are five tips to ensure an easy transition.






