


In today’s Tuesday Tip, I will be addressing the second installment of our two-part series on review analytics. In case you missed it, you can find the first part on Structured Analytics here.
Unlike Structured Analytics, Conceptual Analytics focuses on related concepts within documents, regardless of their text. This emphasis on meaning versus words introduces context into the document analysis. Conceptual Analytics finds documents of the same concepts or topics without necessarily using the same key terms or phrases. In order to use Conceptual Analytics, an analytics Index is needed for the database to find related words, phrases and more. This is made up of four parts:
1. Clustering
Clustering is when the system organizes documents based on concepts, topics or ideas. The system analyzes each documents’ text and groups them together based on the context. These groupings allow users to review documents based on similarity.
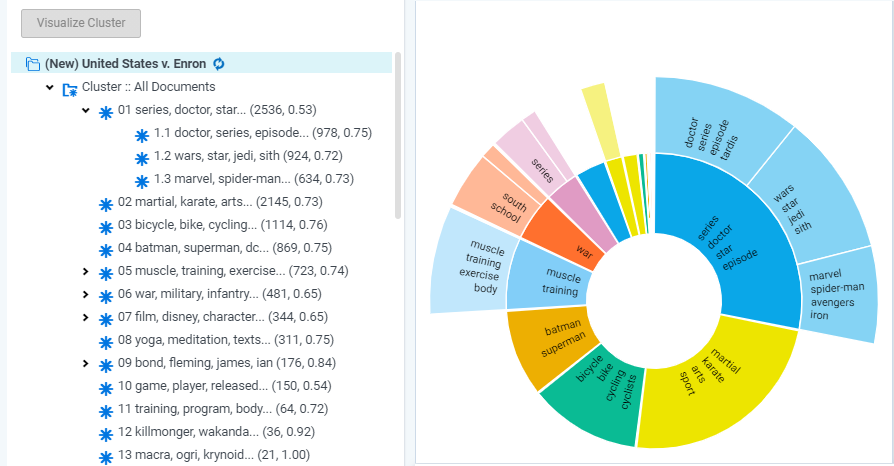
Below is a sample of clusters in Relativity. On the left-hand panel, you can see the different groupings, along with the sub-groupings within. The first number in the brackets indicates the total number of documents within the group and the second indicates the score. The score is the conceptual closeness of all the documents in that cluster. This provides an indication of how closely related the documents are. The higher the score, the more the documents are related to each other.
The right-hand panel in the image below provides a visual of the clusters and their subgroupings. Hovering over a particular cluster will provide you with the total number of documents and the score of the group.
2. Categorization
Categorization works very much like Clustering but the difference between the two is that with Categorization the user is identifying the concepts, ideas or topics and feeding the system samples. The samples could be based on an entire document, phrase or paragraph. Once the samples are provided, the system will find the documents and group them into the appropriate categories based on the documents, phrases or paragraphs that were used. This creates a much more targeted list based specifically on what you are looking for in the context of your review.
3. Concept Searching
Concept Searching allows users to find documents that are similar in concepts or ideas based on a sample phrase or block of text, allowing for prioritization of important documents. When running a concept search query, the documents returned are not based on any specific term in the search or document. Instead, they share conceptual meaning. This is key as people do not write the same way.
For example, when asking a person how they are, one may ask “How are you doing?”, whereas another may say “How’s it going?”. The words in the question are different, but the meaning is the same. Concept Searching analyzes the documents for the meanings and ideas based on the context.
When running Concept Searches in review tools, you are often provided a rank for each document. The rank measures the conceptual closeness of the document to the phrase or text you originally searched. The higher the rank, the closer it is in concept.
4. Predictive Coding
There are two categories that fall within Predictive Coding: Technology-Assisted Review (TAR) and Continuous Active Learning (CAL). Both TAR and CAL work off of the content and context of documents in order to find those that are relevant or potentially relevant. The difference is the algorithms and methods used to train the system to find the documents.
With TAR, reviewers work with a training set of documents that they identify as either Relevant or Not Relevant. TAR is a static model based on the reviewer or subject matter expert’s decision on the seed documents. These documents are then fed back into the system so that the analytics engine can look for similar documents. This method must be manually perfected through several rounds of seed documents.
CAL is the newer and advanced version of TAR. This model is dynamic, meaning that it is continuously updated and perfected based on the coding decisions made by a reviewer and the content of the documents. This is an automated training model that is integrated and occurs as documents are coded.
---
Between this and last month’s Tuesday Tip, you should be ready to tackle the use of analytics during your next review project. If you have questions, be sure to reach out to our team today.
You may also be interested in...

What is Structured Analytics in eDiscovery?
We're breaking down the basics of Structured Analytics and how, when applied correctly, they can contribute towards an effective and efficient review.

eDiscovery 101: 5 Easy Ways to Plan a Successful eDiscovery Project
If you're new to the world of eDiscovery, starting on your first project can be intimidating. Here are five tips to ensure an easy transition.






